- Technical paper
The evolution of forecasting techniques: Traditional versus machine learning methods

Artificial intelligence (AI) has been helping solve business problems for many years. Yet, the success of AI and machine learning (ML) initiatives depend on developing algorithms capable of learning by trial and error to improve performance over time. In many cases, the existing business operations that AI and ML processes supplement are based on logic instructions and if-then rules, or follow a decision matrix.
As technology advances, the applications of AI and ML will continue to revolutionize the business world. For example, the use of AI and ML in forecasting is of immense interest to most enterprises due to its usability across functions. Traditionally, enterprises relied on statistical forecasting methods such as exponential smoothing and linear regressions to guide their decision-making. However, machine learning-based forecasting has replaced traditional methods in many data and analytics initiatives across industries and sectors.
Selecting the most appropriate forecast methodology will play a significant role in the time, effort, and costs involved with the process (figure 1). Here, we take a deeper look at the advantages and disadvantages of traditional versus ML forecasting methods and detail the situations for which each technique might be most effective.
Figure 1. Traditional versus machine learning forecasting

Traditional forecasting
In general, traditional algorithms tend to use predefined techniques and statistical models such as linear regression, autoregressive integrated moving average (ARIMA), and autoregressive integrated moving average with explanatory variable (ARIMAX). The goal of traditional forecasting methods is largely descriptive in nature, aimed at analyzing a univariate dataset or a multivariate dataset with finite, countable, and explainable predictors.
The objective of a forecast model is to estimate future value – usually from historical records of business performance metrics. More specifically, forecasts also include a confidence interval that expresses the level of certainty in a given prediction. In many cases, business performance data might be univariate, meaning that the type of data consists of observations on only a single characteristic or variable.
For instance, in predicting the sales of a fast-moving consumer product – such as dairy products – traditional statistical methods might give a reasonable forecast accuracy based on historical data. This forecast occurs because the number of dimensions that might affect the sales of such products is finite and countable. Though a machine-learning algorithm forecasting sales might provide better accuracy, it will be at the cost of explainability and computing power.
Traditionally, some of the following classical models are used effectively when dealing with univariate data with a high degree of accuracy:
- Moving average
- Simple exponential smoothing (SES)
- Holt-Winters
- Damped exponential smoothing (DES)
- Average of SES, Holt, and DES
- Linear regression
- ARIMA, ARIMAX
- Unobserved component modeling
One of the major features of these classical models is the level of transparency into how they function. The outputs provided by these models can be easily traced (figure 2).
Figure 2. The traditional forecasting process
Machine learning forecasting
ML forecasting algorithms often use techniques that involve more complex features and predictive methods, but the objective of ML forecasting methods is the same as that of traditional methods – to improve the accuracy of forecasts while minimizing a loss function. The loss function is usually taken as the sum of squares due to errors in prediction/forecasting.
The most significant difference between the two methods lies in the manner of minimization. Though most traditional methods utilize explainable linear processes most ML methods use nonlinear techniques for minimizing the loss functions.
Some examples of ML forecasting models used in business applications are:
- Artificial neural network
- Long short-term-memory-based neural network
- Random forest
- Generalized regression neural networks
- K-nearest neighbors regression
- Classification and regression trees (CART)
- Support vector regression
- Gaussian processes
ML methods are computationally more demanding than statistical ones. In many cases, the explainability and interpretability of the models in ML methods may not be fully clear. Yet in business applications with vast amounts of data, ML techniques may be better suited for predictions due to the large number of data features involved and the fact that the algorithm used may not be very linear or straightforward.
In the case of predicting the rate of default for loan applications, the forecast values might be impacted by several thousand factors depending on the customer information. In such scenarios, ML algorithms can outperform statistical methods. One of the added advantages of ML forecasting in this scenario is that an ensemble of different forecasting techniques – both linear and nonlinear – can be combined to achieve higher accuracy (figure 3).
Figure 3. The machine learning forecasting process

Comparing traditional and ML forecasting
To illustrate the differences between traditional and ML forecasting methods, let's explore a business case from a US consumer product goods company.
The model considers the weekly US sales forecast for a cereal manufacturer. The comparison used a statistical forecast for weekly sales ($) using traditional methods. On the other hand, an ensemble ML model was used simultaneously to forecast the product sales ($).
The example is indicative of the differences between the two methodologies in terms of explainability and model accuracy. This example can come to life by delving into the individual predictor variables considered, including but not limited to: month, week, number of days available to ship and transport the product, the pricing of the product, and the sales of competitor products.
We can see the actual weekly sales of a cereal category in 2019 (figure 4), along with the predictions made using traditional forecasting (ARIMAX) and an ensemble ML forecast. The data shows weekly sales forecasting predicted values from both approaches and actual weekly sales for the 12 weeks starting on April 1, 2019. We can also see the differences in error metrics between the two approaches (table 1).
Figure 4. Predicted and actual sales between ML and traditional models
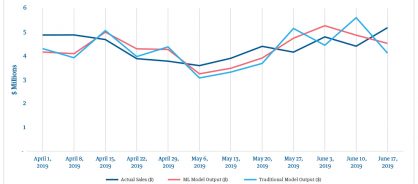
Table 1: Error metric table
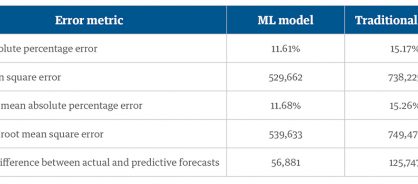
From this, we can see the ML model performed with higher accuracy than the traditional methodology. This result was indicative from the mean absolute percentage error metrics where the ML forecast had a lower value showing higher accuracy in the forecast.
In summary, ML forecasting techniques are highly effective in applications for which the objective is to learn from datasets that have many features – and model explanation is not as critical. For use cases with large datasets, ML forecasting methods seem to perform with higher accuracy – but also have greater computational requirements and are not as explainable. Traditional statistical methods may perform better in univariate applications for which the objective is to analyze and summarize data. This data type has fewer unique features and model transparency and explanations are very much required.
This paper is authored by Sreekanth Menon, AI/ML leader, and Rajeev Ranjan, data science leader, Genpact.
Visit our artificial intelligence services page
Share