- Solution overview
Claims Analytics: Insurance fraud detection solutions
AI and machine learning to cut fraudulent claims

In the US alone, insurance fraud costs insurers a shocking $32 billion every year. But detecting, investigating, and preventing fraud is a massive challenge for even the most mature special investigation unit (SIU).
Our insurance fraud detection solution uses predictive modeling and more than 600 business rules to identify, score, and prioritize possible cases of fraud. It not only reduces insurers' fraudulent claims payouts, but also helps them avoid reputational damage or loss of customers because of premium increases.
How does it work?
Deployed in the cloud or on-site, our fraud service uses AI and machine learning to do the heavy lifting. That way, clients' SIU resources can focus on the highest-value, highest-probability cases of fraud. Our claims fraud solution works by:
- Using a continuous scoring framework that triggers algorithm scoring starting at first notice of loss (FNOL) and then again when new information on a claim becomes available
- Extracting intelligent data (internal and external) to seamlessly connect and aggregate data from multiple disparate data sources and formats
- Using text analytics to build additional indicators from unstructured data such as claim notes and investigation reports
- Using advanced claims analytics to run all suspicious claims through one or more supervised and/or unsupervised machine learning models
- Using link/network analysis to provide investigators with additional leads, analysis, and insights from claims data to capture organized fraud
- Deploying triage analysts to review and analyze the data and refer cases with the highest-risk score to the SIU team
- Using scored but rejected claims to recalibrate models to improve efficiency and accuracy
- Using a case management suite to help investigators keep track of their assigned claims
- Using a visualization suite to enable SIU managers to track model as well as SIU unit performance
Take a copy for yourself
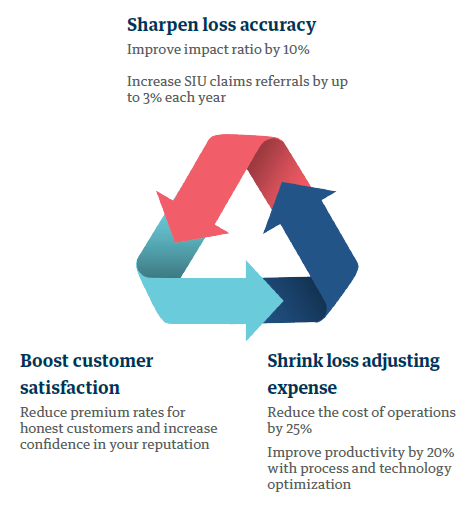
It's a win-win for customers and insurers
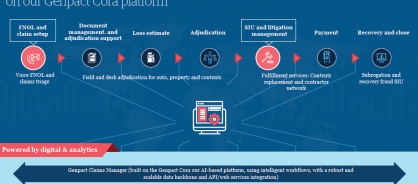
Our end-to-end smart claims approach consists of modular offering built on our Genpact Cora platform
Genpact and claims
Ever-increasing auto and natural catastrophe claims. Rising customer service demands. Aging legacy systems. These are just some of the challenges facing insurers – challenges that digital technologies like automation, AI, and analytics can help tackle. Our digital tools optimize the balance between customer satisfaction, accurate loss assessment, and loss adjusting expenses, with solutions that span the claims journey, handling everything from fast-track claims processing to fraud and subrogation analytics. You can start with the module that addresses your biggest challenge and add from there. Or we can run your entire claims operation.
Global insurers and reinsurers, surplus lines insurers, a European insurer, even a top-10 Fortune company – we've transformed claims analytics for them all over the past 15 years. We combine the digital understanding of an insurtech with claims expertise and business process know-how. Let's put this to work for you.
Visit our insurance services page
Share